






一鍵體驗Qwen3、DeepSeek等熱門鏡像,更低價格享高性能GPU云主機提供更適合大尺寸模型的裸金屬實例,獨占整機資源,性能無損模型訓練和推理、AI繪畫與視頻,數字人直播等豐富業務場景解決方案
千人加購
RTX40系-48G
火爆預約中
RTX50系




9.9元起暢享高性能GPU云服務器
GPU產品新用戶均可參與,同一用戶限試用一種機型。活動截止至2025年12月31日。

多卡專區,成本直降
多卡型1.1折起,RTX40系低至3.1折,新老同享續費同價。
應用場景
中小規模訓練/推理
圖像分類、語音識別,單次推理耗時短,并發量低
教學培訓/個人學習
輕量級任務,成本敏感度高
開發測試環境
代碼調試,小模型驗證,算力需求波動大
產品優勢

多卡型適配多場景
A/H/RTX系列多款卡型為訓練和推理提供可靠算力支撐,打造可拓展的GPU加速服務平臺;

性能卓越安全可靠
安全可靠的網絡環境和防護服務,高擴展集群提升多卡協作效率滿足分布式訓練需求;

高性價比開箱即用
涵蓋各類熱門主流鏡像,封裝多版本CUDA和驅動,提供開箱即用的AI基礎架構能力;

產品靈活與定制化
客戶需求響應快,提供私有化部署方案,適配客戶復雜的IT環境為其節省IT支出;


, 物理獨享, 性能拉滿
AI大模型訓練/微調
需持續高算力、無中斷,顯存占用>50GB
HPC高性能計算
需微秒級延遲、計算結果零誤差
自動駕駛模型
需7×24小時穩定響應,拒絕延遲波動
實時圖形渲染
需幀率穩定>60fps、延遲<20ms
在售裸金屬的性能參數說明
| 型號 | 顯存 | CPU | 內存 | 系統盤 | 數據盤 |
|---|---|---|---|---|---|
| RTX40系 | 24G*8 | AMD 9354*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| RTX40系(高顯存) | 48G*8 | INTEL 6530*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| RTX50系 | 32G*8 | INTEL 6530*2 | 1024G | 960G SSD*2 | 7.68T Nvme*1 |
| A系列 | 80G*8 | INTEL 8358*2 | 1024G | 960G SATA*2 | 7.68T Nvme*1 |
| H系列 | 141G*8 | INTEL 8468*2 | 2048G | 960G Nvme*2 | 4.84T Nvme*8 |
點擊【立即咨詢】查看配置方案和最新報價。
產品優勢

物理獨占極致性能
物理機資源獨享,滿足高安全與合規要求,無虛擬化損耗,GPU/網絡/存儲性能100%釋放;尤其適合對計算、存儲和網絡吞吐有極致要求的場景

安全與合規性更高
金融風控、政務大數據、軍工仿真等領域,對“數據物理隔離”的強制要求,裸金屬支持自定義安全策略,進一步降低攻擊面。

定制優勢硬件可配
多卡并行,GPU間通過NVLink/NVSwitch高速互聯,用戶可自主安裝任意版本GPU驅動、操作系統,深度滿足用戶需求。

高負載場景成本低
裸機交付,無虛擬化層額外成本,適合7×24小時滿負載運行場景,充分利用整機資源,避免“為峰值付費”的浪費。
應用場景
AI工具/AI應用
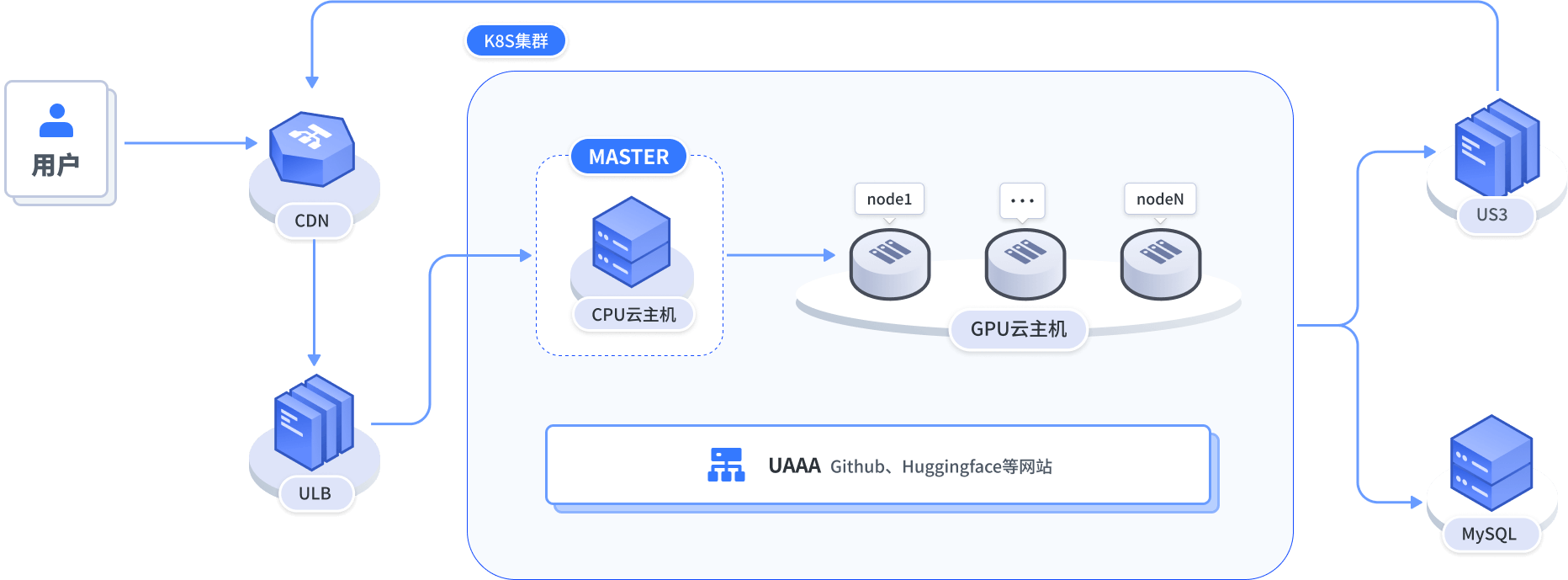
高并發業務快速縮擴容、輕松應對業務洪峰
- 娛樂社交、實時美顏、云上極速處理、低延時處理提升用戶使用體驗 根據CPU/GPU利用率自動擴縮容美顏處理Pod,應對直播高峰流量(如晚間8-10點自動擴容至3倍實例)
- 智能剪輯、一鍵生成視頻 批量處理用戶上傳視頻時,創建臨時任務Pod完成轉碼/特效渲染后自動回收資源
- AI換臉/表情包 基于消息隊列長度(如RabbitMQ積壓數)觸發彈性伸縮,而非傳統CPU指標,隔離用戶上傳的人臉數據僅允許流向指定模型推理Pod
立即咨詢
美顏換臉視頻剪輯視頻生成
客戶案例
